CSS Selector Exclusion & Real-time scraping status
Scraped pages include headers, footers, and ads that degrade AI response quality. This update lets you exclude unwanted HTML elements globally while customizing exceptions for specific URL
CSS Selector Exclusion
Control which HTML elements are scraped from web pages using CSS selectors.
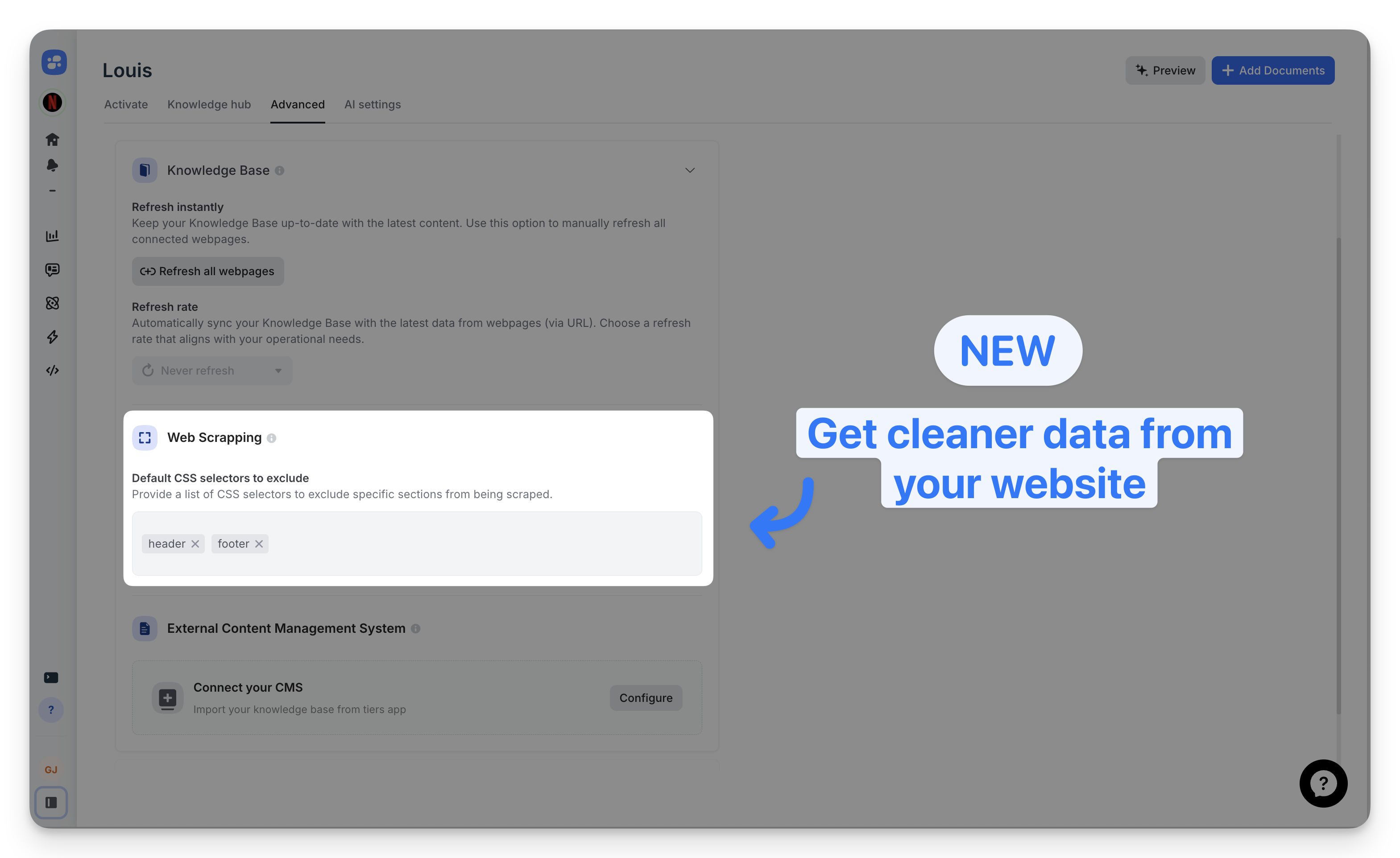
Default global exclusions
Set CSS selectors that apply to all scraped URLs in Advanced > Web Scraping. Common selectors include header, footer, .sidebar, and .ad.
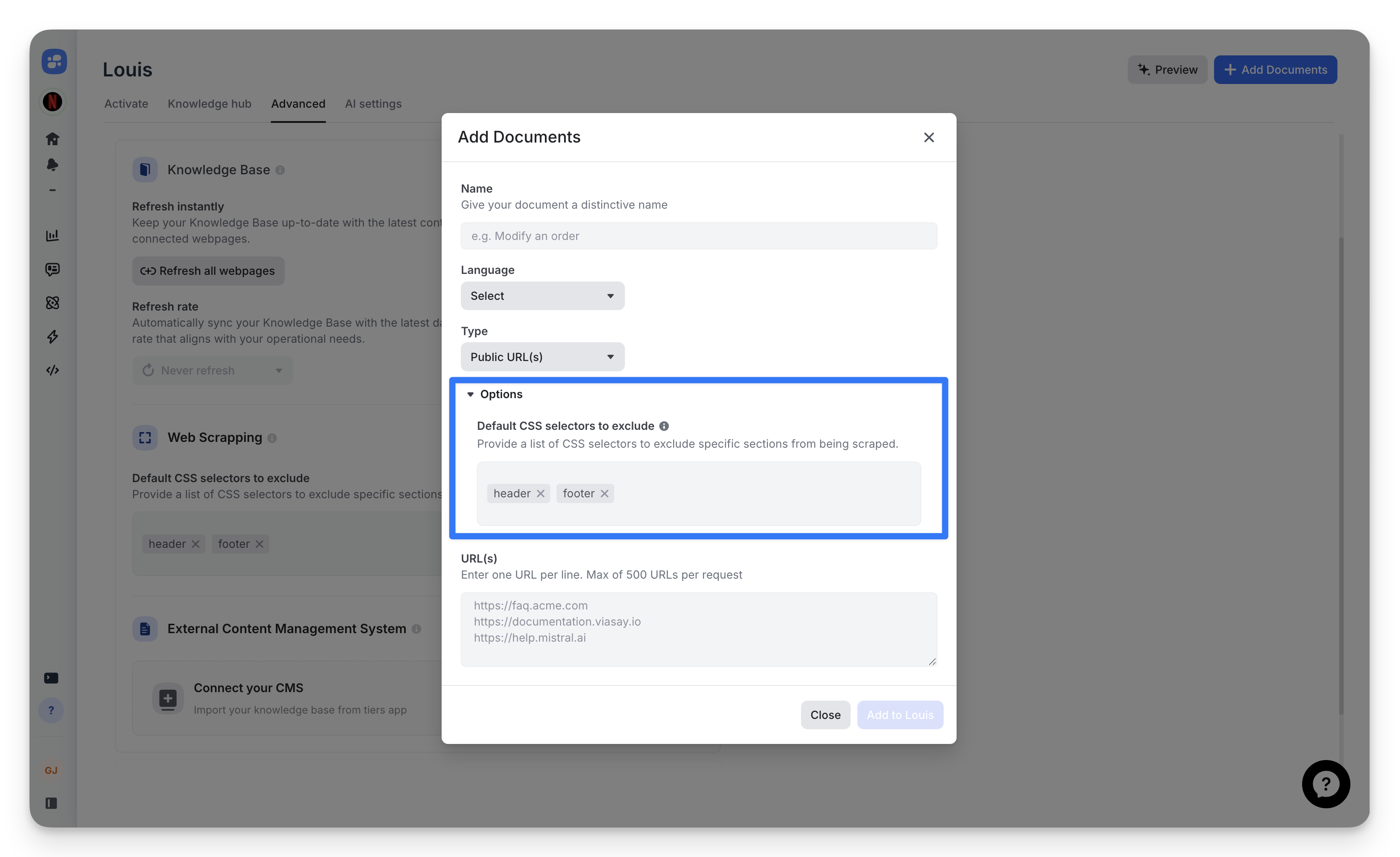
URL-specific overrides
Override default exclusions when importing individual URLs. Expand the Options section in the Add Documents modal to customize selectors for specific pages without changing global defaults.
Persistent configuration accross refreshes
CSS selector settings persist across all refreshes and automatic synchronizations. Your exclusion rules remain active whenever content is re-scraped
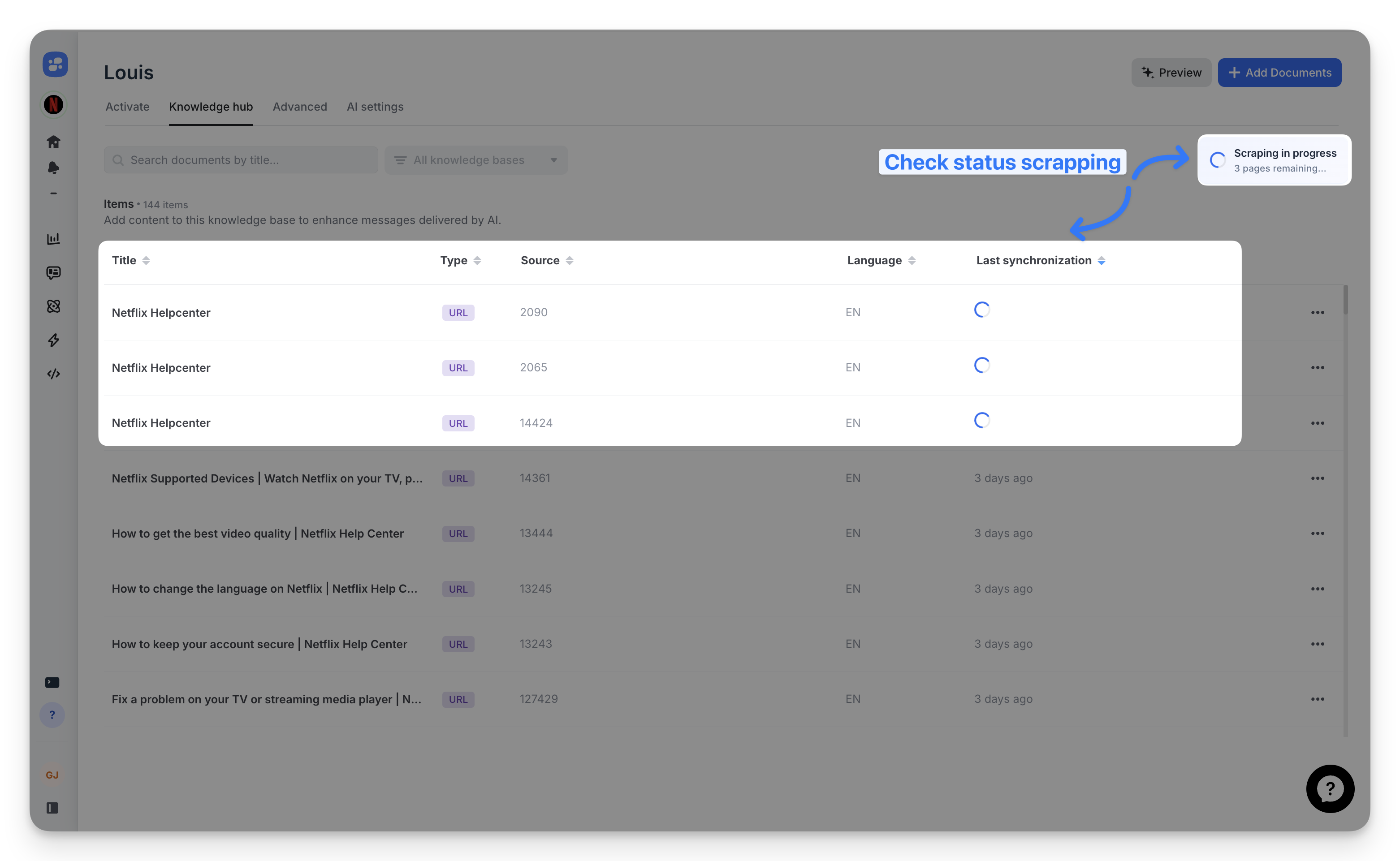
Real-time scraping status
Track import progress directly in the Knowledge hub. Active scrapes display a spinner icon with a tooltip showing remaining pages
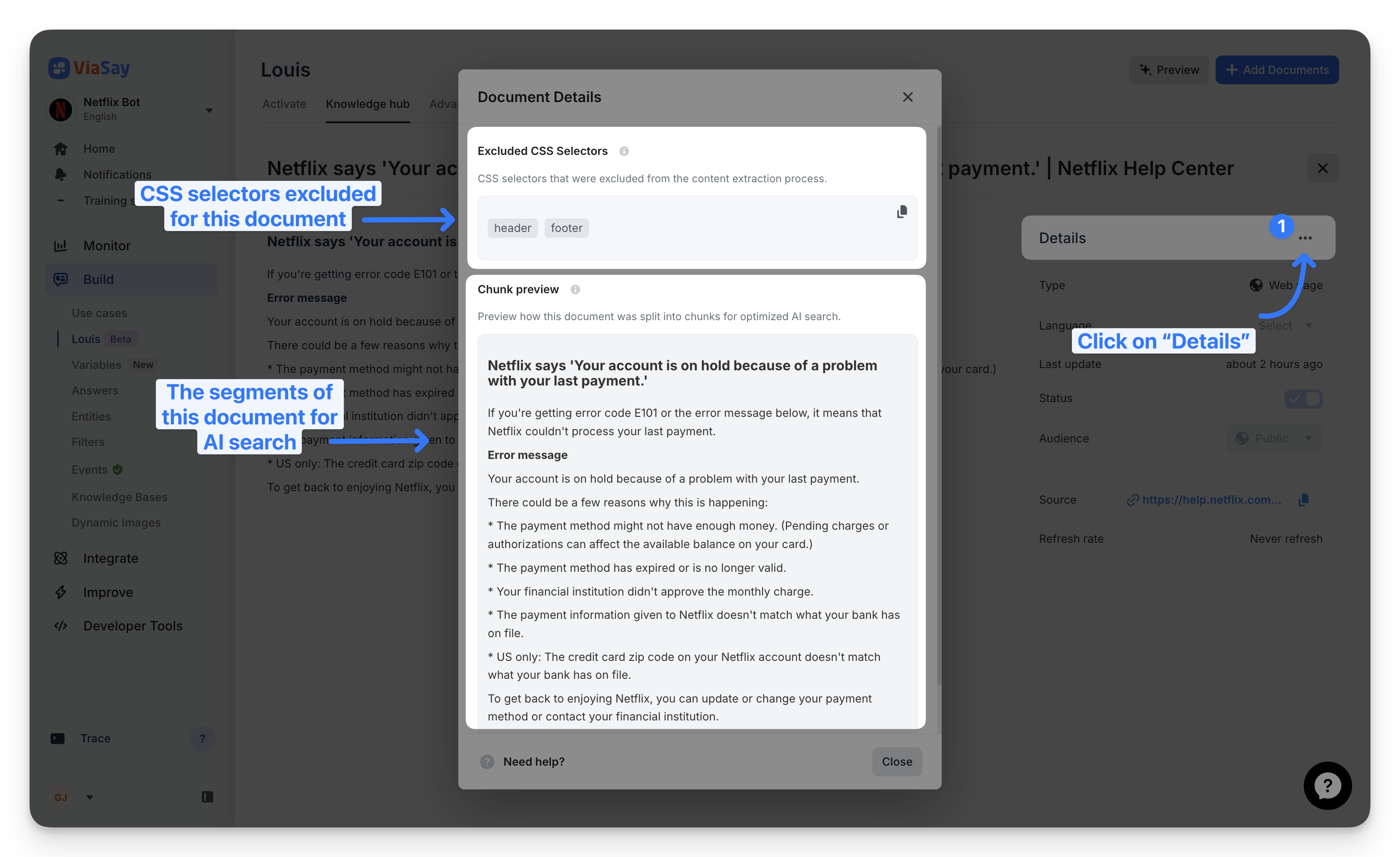
Inspecting document details
Access detailed information about any document through the Knowledge hub. The Document Details modal shows which CSS selectors were excluded and provides a chunk preview to validate content segmentation quality.